What is DRDA? zIIPs and Distributed Db2 SQL

When it comes to exploiting the zIIP specialty processor, a lot of attention is paid to distributed Db2 SQL requests, and rightly so. Distributed SQL issued against Db2 is one of the largest opportunities for reducing stress on general purpose processors. Indeed, most modern applications that access Db2 data do so using dynamic SQL using DRDA.
But let’s back up a moment and take a look at some of these terms and what they mean.
What Exactly Is DRDA?
DRDA stands for Distributed Relational Database Architecture, and it is a set of protocols designed by IBM and is now supported as a database interoperability standard by The Open Group. It provides specifications to enable users to access distributed data regardless of where it physically resides. Using DRDA, a DBMS can coordinate communication among distributed locations, thereby establishing an open, heterogeneous distributed database environment. This allows applications to access multiple remote tables at various locations and have them appear to the end-user as if they were a logical whole.
A distinction must be made between the architecture and the implementation. DRDA describes the architecture for distributed data and nothing more. It defines the rules for accessing the distributed data, but it does not provide the actual application programming interfaces (APIs) to perform the access. So DRDA is not a program, but provides the specifications for a program.
When a DBMS is said to be DRDA-compliant, all that is implied is that it follows the DRDA specifications. Db2 is a DRDA-compliant RDBMS product. DRDA is only one protocol for supporting distributed RDBMS. Of course, if you are a Db2 user, it is probably the only one that matters, as it is the one that IBM supports.
DRDA Functions
Three functions are defined by DRDA to provide distributed relational data access:
• Application Requester (AR)
• Application Server (AS)
• Database Server (DS)
The DRDA application requester (AR) function accepts SQL requests from an application and sends them to the appropriate application server (or servers) for subsequent processing. Using this function, application programs can access remote data.
In theory, if all the data you are interested in is physically located somewhere else (that is, remote), there may be no need for a local RDBMS, and DRDA does not require the requester to run on a system with a local RDBMS.
The DRDA application server (AS) function receives requests from application requesters and processes them. These requests can be either SQL statements or program-preparation requests. The AS acts upon the portions that can be processed and forwards the remainder to DRDA database servers for subsequent processing. This is necessary if the local RDBMS cannot process the request.
The AR is connected to the AS using a communication protocol called the Application Support Protocol, which is responsible for providing the appropriate level of data conversion. This is only necessary when different data representations are involved in the request. An example of this is the conversion of ASCII characters to EBCDIC (or vice versa).
The DRDA database server (DS) function receives requests from application servers or other database servers. These requests can be either SQL statements or program preparation requests. Like the application server, the database server will process what it can and forward the remainder on to another database server.
A database server request may be for a component of an SQL statement. This would occur when data is distributed across two subsystems, and a join is requested. The join statement is requesting data from tables at two different locations. As such, one portion must be processed at one location; the other portion at a different location.
Because the database servers involved in a distributed request need not be the same, the Database Support Protocol is used. It exists for the following reasons:
• To connect an application server to a database server
• To connect two database servers
Like the Application Support Protocol, the Database Support Protocol ensures the compatibility of requests between different database servers.
The Five DRDA Levels
There are five levels within DRDA. Each level represents an increasing degree of distributed support. Additionally, the levels reflect the number of requests and RDBMSes per unit of work and the number of RDBMSes per request.
In order of increasing complexity, the five DRDA levels are:
• User-Assisted Distribution – the simplest form of distributed data access whereby the end user must be aware of and code for the distributed access.
• Remote Request – a single SQL statement can be issued to read or modify a single remote RDBMS within a single unit of work. It enables developers to be operating within one RDBMS and refer to a different RDBMS.
• Remote Unit of Work (RUW) – multiple SQL statements are permitted, but it is possible to read and/or modify only a single remote RDBMS within a single unit of work.
• Distributed Unit of Work (DUW) – multiple SQL statements can be issued to read and/or modify multiple RDBMSes within a single unit of work. However, only one RDBMS can be specified per SQL statement.
• Distributed Request – enables complete data distribution; multiple SQL requests, both distributed and non-distributed, can be contained within a single unit of work. Distributed request enables a single SQL statement to read and/or update multiple RDBMSes at the same time.
IBM Db2 for z/OS and DRDA
IBM implements DRDA to deliver distributed data access capabilities within the Db2 Family of database systems. However, it does not, as of yet, provide DRDA distributed request capability.
The Distributed Data Facility (DDF) is required for accessing distributed data through Db2. Although DDF is an optional Db2 address space, it is required if you want to support distributed access to Db2 data.
Distributed Db2 connections are defined using Db2 Catalog system tables. Each Db2 subsystem is identified by a unique location name of up to 16 characters, which can be explicitly accessed using CONNECT or three-part table names.
The DRDA AR function is delivered for Db2 using the IBM Data Server driver or IBM Db2 Connect. There are several ways to configure the connectivity, but for the most part, modern connectivity is established using the IBM Data Server Driver or Client instead of using the Db2 Connect Gateway. Nevertheless, each client connecting to Db2 for z/OS still requires a license to do so.
What About zIIPs?
SQL requests that use DRDA to access Db2 for z/OS over TCP/IP connections are zIIP eligible, with up to 60% of their instructions running on the zIIP. The vast majority of new applications are being written using dynamic SQL to access distributed Db2 data. That means that some portion of the workload, up to 60% of it, can be redirected to run on zIIPs instead of on the general-purpose CPU.
One way to take advantage of the zIIP eligibility of distributed Db2 SQL is to convert some of your traditional COBOL workloads to Java. Instead of the local, static SQL used by most COBOL programs, using the IBM Data Server Driver for JDBC and SQLJ to run these converted Java applications makes them zIIP-eligible. And therefore, such conversions can help to reduce the cost of your mainframe environment.
Are you interested in more information about zIIP and its role in reducing mainframe costs? Check out this eBook: From A to zIIP – Leveraging the IBM Specialty Processor for Mainframe Cost Savings.

Cost containment is an important criterion for IT departments as organizations everywhere embrace financial austerity. Every decision regarding your computer resources is weighed based on not only the value that it can deliver to your organization, but upon the cost to procure, implement, and maintain. And in most cases, if a positive return on investment cannot be calculated, the software will not be adopted, or the hardware will not be upgraded.
One area that many organizations are pursuing to reduce costs is mainframe application modernization. CloudFrame supports these efforts with its solutions for converting COBOL to Java. Such conversion can modernize the code and reduce costs by running the converted code on zIIP processors.
But how does that work? The total cost of mainframe computing can be high, and software is the biggest portion of that cost. The pricing model for most mainframe software remains based on the capacity of the machine on which the software runs. Note, however, that this pricing model will determine the actual cost, and it can vary dramatically from model to model. Our intent here is not to describe in detail how all the different IBM pricing models work. Although sub-capacity pricing models are the most commonly used, there is no widespread appreciation for how this actually works to lower costs other than a vague notion that the monthly costs are based on usage instead of capacity. And that is true, but the devil is in the details.
The most popular sub-capacity pricing models IBM mainframe shops use are variable workload license charging (VWLC) and advanced workload license charging (AWLC). There are nuances to each of these, but, for the most part, they function the same way at a high level. They are monthly license pricing metrics designed to match software cost more closely with its usage. Some of the benefits of these models include the ability to grow hardware capacity without necessarily increasing your software charges, pay for key software at LPAR-level granularity, experience a lower cost for incremental growth, and manage software cost by managing workload utilization.
So, how does it work? The first thing to understand is that most of IBM’s system software is categorized as monthly license charge (MLC) software. This means you pay for it monthly. Examples of MLC software include z/OS, Db2, IMS, CICS, MQSeries, COBOL, and others.
Basically, what happens with sub-capacity pricing metrics is that your MSU usage is tracked and reported by LPAR. You are charged based on the maximum rolling four-hour average (R4HA) MSU usage. MSU usage is continuously measured, and the R4HA is calculated. Every five minutes, a new measure of instantaneous MSU usage is taken, with the oldest measurement being discarded. Then a new average is calculated.
The R4HA is tracked continuously, for each LPAR, over the course of the month. Then the metrics are evaluated based on the products installed in the LPARs. You are charged by product based on the peak utilization of the LPARs where that product runs. All this information is collected and reported to IBM using the SCRT (Sub Capacity Reporting Tool). It uses the SMF 70-1 and SMF 89-1 / 89-2 records. So, you pay for what you use… sort of.
You actually pay based on LPAR usage, not product usage. Consider, for example, if you have IMS and CICS both in a single LPAR, but IMS is used only minimally, and CICS is used a lot. Since they are both in the same LPAR, you would be charged for the same amount of usage for both. But it is still better than being charged based on the usage of your entire central electronics complex (CEC), right?
Determining Where to Focus Your Cost Containment Efforts
The next step needs to be understanding how to focus your cost containment efforts using your knowledge of how IBM monthly software costs are charged. Over the course of the month, we have collected the R4HA for every LPAR every five minutes. The bill will be calculated using the peak R4HA utilization metric for the LPAR (or LPARs) for each MLC product you have licensed.
Assume that we have three LPARs: TEST, PRDA, and PRDB. Further, assume that we have z/OS in all three LPARs, Db2 in TEST and PRDB, and IMS in PRDA only. In this case, the cost for z/OS will be based on the combined peak for all three LPARs, the cost for Db2 for the peak of just TEST and PRDB, and the cost for IMS based on just the peak of PRDA. As the number of products and combinations of LPARs on which they run expands, the complexity of determining the impact of tuning and modernization for cost control increases.
Simplifying the Goal
Start by identifying the monthly R4HA utilization peaks. This information is provided in the monthly SCRT report that you deliver to IBM for billing. Typically, this report is produced by a systems programmer or capacity planner for delivery to IBM. The SCRT cross-references LPAR utilization and product execution by LPAR are used to determine the maximum concurrent LPAR rolling four-hour average utilization.
The P5 section of the SCRT report will show your products, the LPARs where they run, and the date/time of the peak for the month. For example, here is the P5 section of an example SCRT report: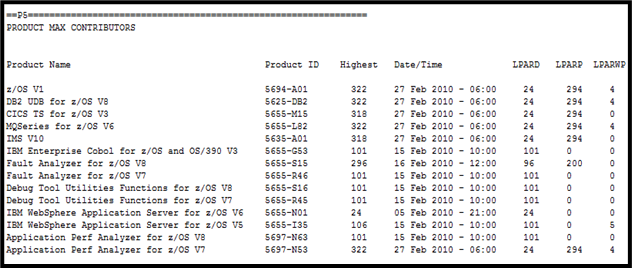
It bears repeating… MLC products are charged based on the peak R4HA utilization of the LPARs in which the sub-capacity products execute. The SCRT determines the required license capacity by examining, for each hour in the reporting period, first the four-hour rolling average utilization by LPAR and then which eligible products were active in each LPAR.
Each month you must run an SCRT report for IBM to determine your monthly billing. But you can also use it to pinpoint the specific peak workloads that contribute to your monthly MLC software bill. In the case of the report shown here, we see several peaks worth examining:
- The largest occurs on February 27 at 6 AM and represents the peak when a product runs in all three LPARs on the report.
- Another occurs on February 16 at 12 Noon for products that run in the first two LPARs.
- Other occur on February 15 at 10 AM and February 5 at 9 PM.
Using this information, you can focus on the workload that runs in these LPARs during these peak timeframes. Reducing the MSUs consumed during these peak times can reduce your monthly software bill, either by reducing the MSUs consumed and reported for the peak in question or by reducing the MSUs for the peak such that it is no longer the peak.
The Bottom Line
If you want to reduce software costs by reducing MSU usage, then it is important that you understand how charges are calculated. This article gives a high-level overview of the approach. In my next article, I will talk about the iterative nature of tackling mainframe software cost containment.
© 2022 Craig S. Mullins
Related Post

Why modernization is hard? – Series 1
COBOL has its own rules for calculations that are hard to replicate…

Strategies for Modernizing the Mainframe Experience
You may have recently read The Benefits and Challenges of Mainframe Application…
Recent Comments